Modern clinical trial designs often rely on commercial software platforms. They are easy to use, can present results in a straightforward manner, and bring nice visualizations. The major drawbacks for many may be threefold: 1) the underlying methological assumptions can be like a black box to users, which may lead to the second drawback, 2) lack of flexibility and interpretability from the strategic perspective, and 3) is prone to error without a proper validation process, particularly in high-pressure, fast-paced environments. As the design paradigm steadily shifts to the Bayesian framework, simulation can be a powerful tool to assist advanced clinical trial design and enhance communication and collaboration between stakeholders.
Simulation lies on the distribution assumption of data. Data that follow distributions, such as normal, binomial or Poisson distributions, can be generated by a single function of a typical statistical programming language. When it comes to simulating survival data, a frequently used endpoint of many of today’s clinical trials, it may take a set of comprehensive steps, involving generating two variables, a time and a censoring variable. For the survival data with a mixture distribution or a piecewise hazard function, the steps are beyond simply generating two variables, each following a basic distribution. There are a few choices in R that can be found to assist generating such types of survival data. I have recently run a few design scenarios with the simsurv package, made a side-by-side comparison with the gsDesign package, the gsDesign2 package as well as the EAST® Software by Cytel, and found they have a high degree of alignment. The simsurv R package creators also published a tutorial paper in the Journal of Statistical Software that showed cases of simulating survival data from standard parametric distributions (e.g. exponential, Weibull) to complex situations, such as a user-defined or time-dependent hazard function. These situations may facilitate survival data generated under extreme distributions that may fit in design scenarios for pseudo-progression, delayed treatment effects, treatment crossovers, rare diseases or such.
Once there is a way to generate the desired survival data (time-to-event endpoints), a trial can be designed under either a frequentist or a Bayesian framework. In addition, the trial outcome can be anticipated with the simulated data prior to its initiation, and also be updated as the trial is at an interim look.
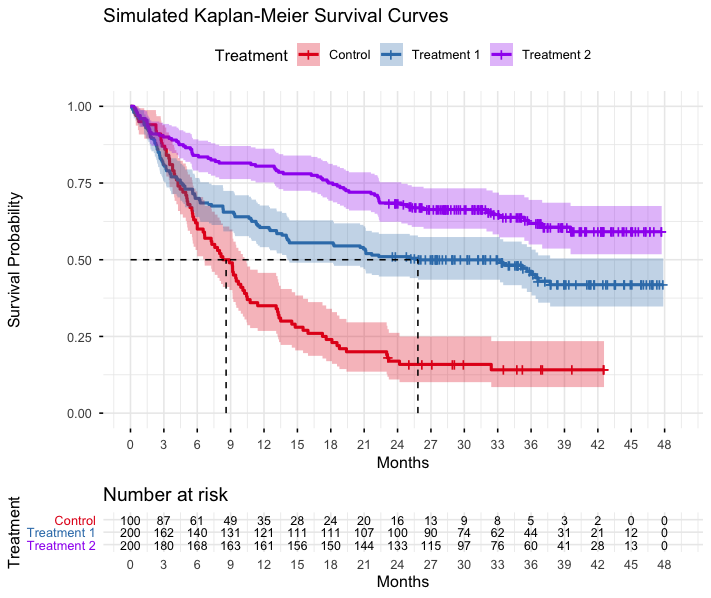
Simulated survival data with a piecewise hazard assumption for the control treatment, and non-proportional hazard ratios for the two experimental treatments against the control.